
personal code review practices, mark Ⅱ
Just about two months ago, I posted about my revived “work through some tickets in each queue then rotate” strategy. When I had first tried to do it, I hadn’t had enough discipline, and it failed. After a month, it seemed to be going very well, because of two minor changes:
- I replaced “remember where I was in the list” with “keep the list in a text file.”
- I used The Daily Practice to keep track of whether I was actually getting work done on the list regularly.
About a month later, I automated step 2. I just had my cron job keep track of the SHA1 of the file in git. If it changed, I must have done some work.
Yesterady, as I start month three of the regime, I’ve invested a bit more time in improving it, and I expect this to pay big dividends.
My process is something like this, if you don’t want to go read old posts:
- keep a list of all my projects
- group them into “bug queue cleared” and “project probably complete” and “work still to do”
- sort the lists by last-review date, descending; fall back to alphabetical order
- every time I sit down to work on projects, start with the first project on the “work to do” list, which has been touched least recently
- when new bugs show up for the other two lists, put them into the “work to do” list at the right position
This was not a big problem. I kept the data in a Markdown table and when I’d finish review, I’d delete a line from the top, add it to bottom, and add today’s date. The step that looked like it would be irritating was #5. I’d have to keep an eye on incoming bug reports, reorder lists, and do stupid maintenance work. Clearly this is something a computer should be doing for me.
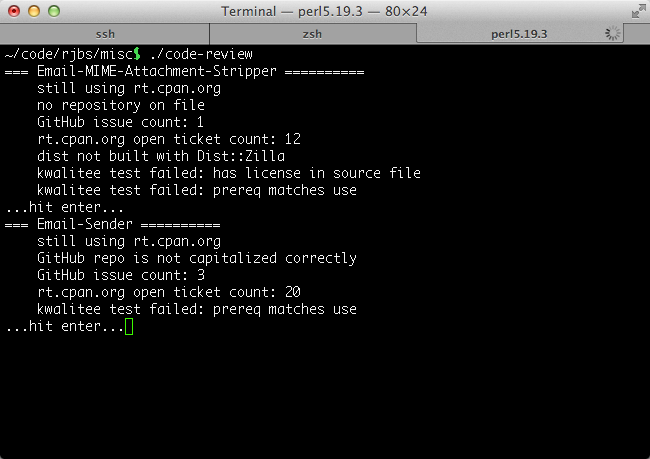
So, the first question was: can I get the count of open issues in GitHub?
Answer: yes, trivially. That wasn’t
enough, though. Sometimes, I have older projects with their tickets still in
rt.cpan.org. Could I find out which projects used which bugtracker? Yes,
trivially. What if the project
uses GitHub Issues, but has tickets left in its RT queues? Yes, I can get
that.
Those are the big things, but once you pick up the data you need for figuring them out, there are other things that you can check almost for free: is my GitHub repo case-flattened? If so, I want to fix it. Is the project a CPAN dist, but not built by Dist::Zilla? Did I forget to enable Issues at GitHub? Am I missing any “Kwalitee point” on the CPANTS game scoreboard?
Writing the whole program took an hour, or maybe two, and it will clearly save
me a fair bit of time whenever I do project review. I even added a
--project switch so that I can say “I just did a round of work on
Some::Project, please update my last reviewed date.” It rebuilds the YAML file
and commits the change to the repo. Since it’s making a commit, I also added
-m so I can specify my own commit message, in case there’s something more to
say than “I did some work.”
This leaves my Markdown file in the lurch. That wouldn’t bother me, really, except that I’ve been pointing people at the Markdown file to keep track of when I might get to that not-very-urgent bug report they filed. (I work on urgent stuff immediately, but not much is urgent.) Well, no problem here: I just have the program also regenerate the Markdown file. This eliminates the grouping of projects into those three groups, above. This is good! I only did that so I could avoid wasting time checking whether there were any bugs to review. Now that my program checks for me, there’s no cost, so I might as well check every time it comes up in the queue. (Right now, it will still prompt me to review things with absolutely no improvements to be made. I doubt this will actually happen, but if it does, I’ll deal with it then.)
The only part of the list that mattered to me was the list of “stuff I don’t really plan to look at at all.” With the automation done, the list shrinks from “a bunch of inherited or Acme modules” into one thing: Email-Store. I just marked it as “never review” and I’m done.
So, finally, this is my new routine:
- If The Daily Practice tells me that I have to do a code review session…
- …or I just feel like doing one…
- …I ask
code-reviewwhat to work on next. - It tells me what to work on, and what work to do.
- I go and do that work.
- When I’m done, I run
code-review --project That-Projectand push to github. - Later, a cron job notices that I’ve done a review and updates my daily score.
Note that the only part of this where I have to make any decisions is #5, where
I’m actually doing work. My code-review program (a mere 200 lines) is doing
the same thing for me that Dist::Zilla did. It’s taking care of all the stuff
that doesn’t actually engage my brain, so that I can focus on things that are
interesting and useful applications of my brain!
My code-review program is on GitHub.